
Neue Pipeline in Fabric anlegen
Wechsle in deinen Fabric-Arbeitsbereich und erstelle ein neues Element vom Typ Data Pipeline.
- Klicke auf „Neu“ → „Data Pipeline“
- Vergib einen aussagekräftigen Namen (z. B. SPDR Sector 5D Performance)
Nach der Erstellung öffnet sich die Pipeline-Oberfläche. Dort kannst du direkt mit dem ersten Baustein beginnen.
Data Pipeline über die Kachel auswählen and Namen vergeben.
Quelle einrichten: SPDR API anbinden
Ziehe den Baustein „Daten kopieren“ in die Pipeline. Bei den Konfigurationen ist unter Quelle die API Verbindung anzugeben
URL der SPDR-API ein: https://www.sectorspdrs.com/api/cms/sector-overview?period=5D
Wähle als Quelle die Option Web / REST API
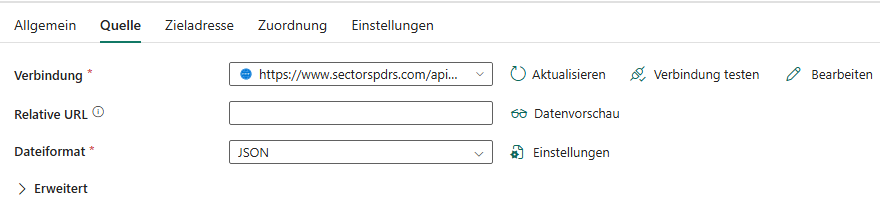
👉 Tipp: Falls die API später andere Zeiträume haben soll (z. B. 1D, 1M, YTD), kannst du diesen Parameter flexibel ändern.
3. Ziel definieren: OneLake als Speicher
- Klicke auf “Daten speichern”.
- Ziel: OneLake Data Lakehouse
4. Automatisierung
- Plane die Aktualisierung direkt in Fabric: “Zeitplan” → täglich / stündlich.
- So hast du immer die aktuellen 5-Tages-Daten im Lake.
- Optional: Alerts aktivieren, wenn die Pipeline fehlschlägt.
5. Nutzung in Power BI oder Fabric Notebooks
- In Power BI kannst du den Lakehouse/Table direkt anbinden.
- Typische Visualisierungen:
- Heatmap der Sektorperformance
- Vergleich Top vs. Flop Sektoren
- Historische Entwicklung (wenn du mehrere Läufe speicherst)
Vorteile des Low-Code-Ansatzes
- Kein Python, keine SDKs, keine Service Principals → schneller Einstieg.
- Alles läuft innerhalb von Fabric, mit einfachem Monitoring.
- Leicht für Analysten und Fachbereiche zu pflegen.
- Trotzdem sauber strukturiert (Parquet/Delta + Partitionierung).